To develop computer vision models assessing lineups of residual plots, we need to define a numerical measure of “difference” or “distance” between plots.
pixel-wise sum of square differences
Structural Similarity Index Measure (SSIM)
scagnostics
…
📏KL Divergence of \(P\) from \(Q\)
We defined a distance measure based on Kullback-Leibler divergence to quantify the extent of model violations
\[\begin{align}
\label{eq:kl-0}
D &= \log\left(1 + \int_{\mathbb{R}^{n}}\log\frac{p(\boldsymbol{e})}{q(\boldsymbol{e})}p(\boldsymbol{e})d\boldsymbol{e}\right), \\
\end{align}\]
\(P\): reference residual distribution assumed under correct model specification.
\(Q\): actual residual distribution.
\(D = 0\) if and only if \(P \equiv Q\).
However, \(Q\) is typically unknown \(\Rightarrow\)\(D\) can not be computed.
🎯Estimation of the Distance
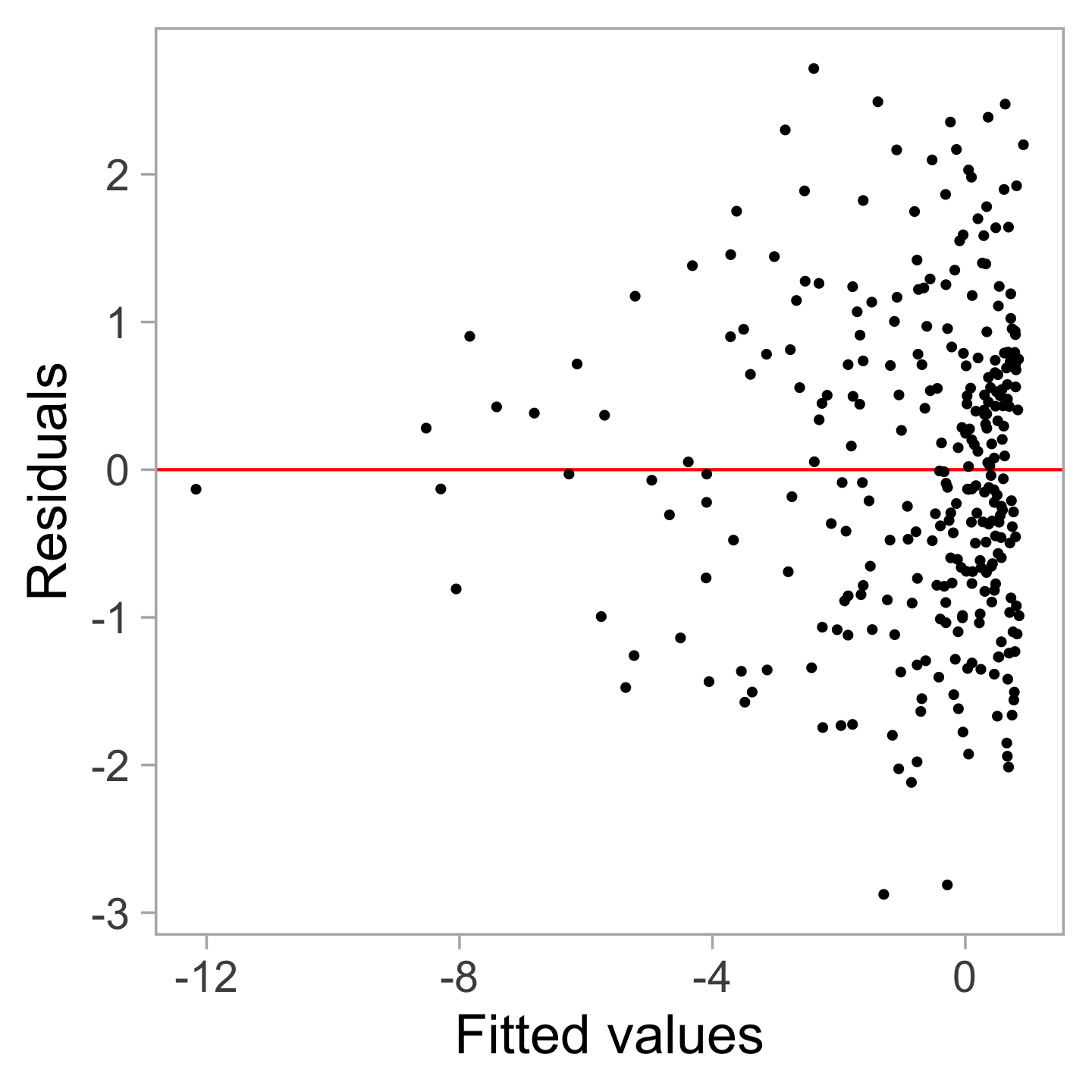
We can train a computer vision model to estimate \(D\) with a residual plot
where \(V_{h \times w}(.)\) is a plotting function that saves a residual plot as an image with \(h \times w\) pixels, and \(f_{CV}(.)\) is a computer vision model which predicts distance in \([0, +\infty)\).
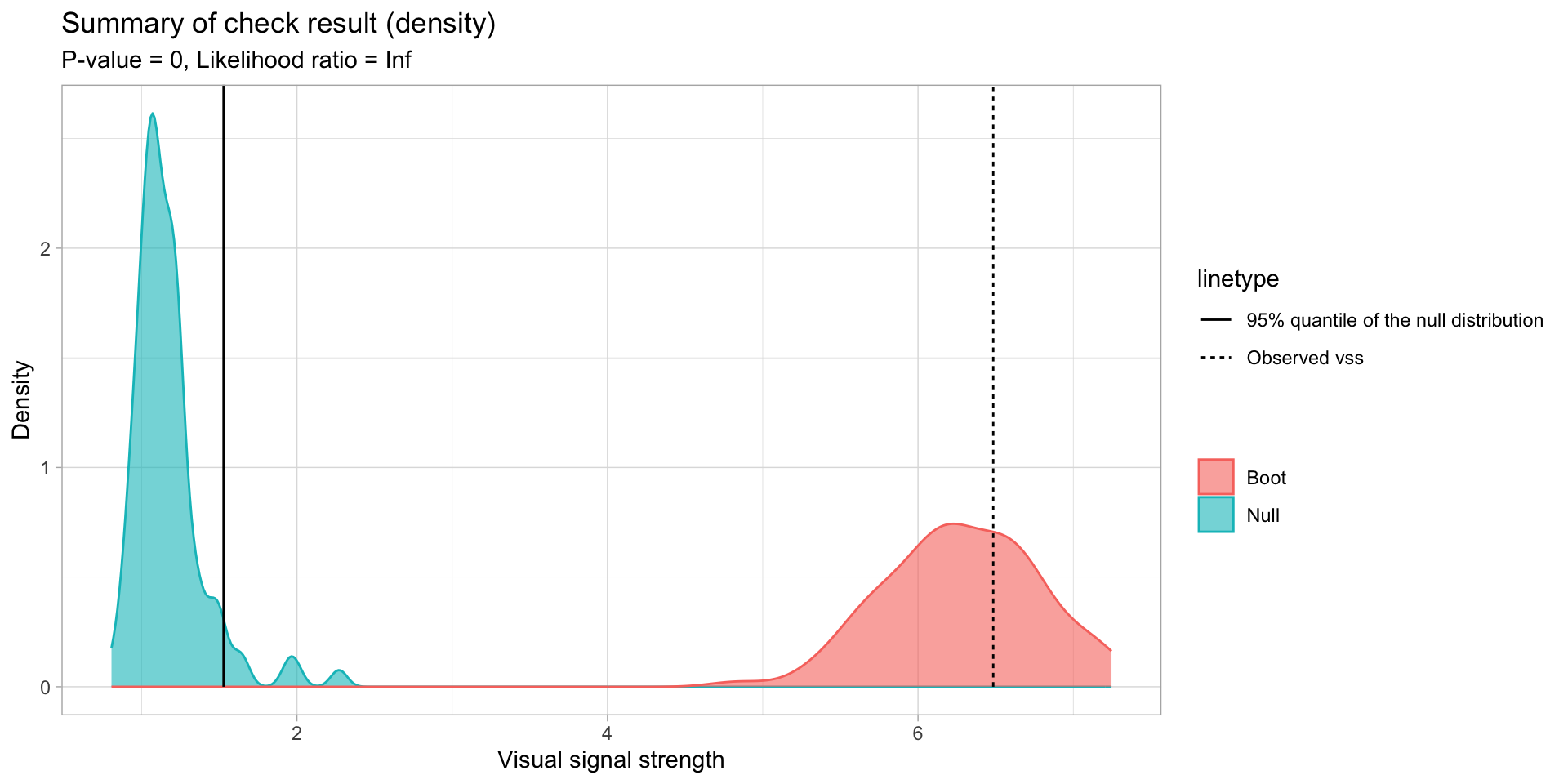
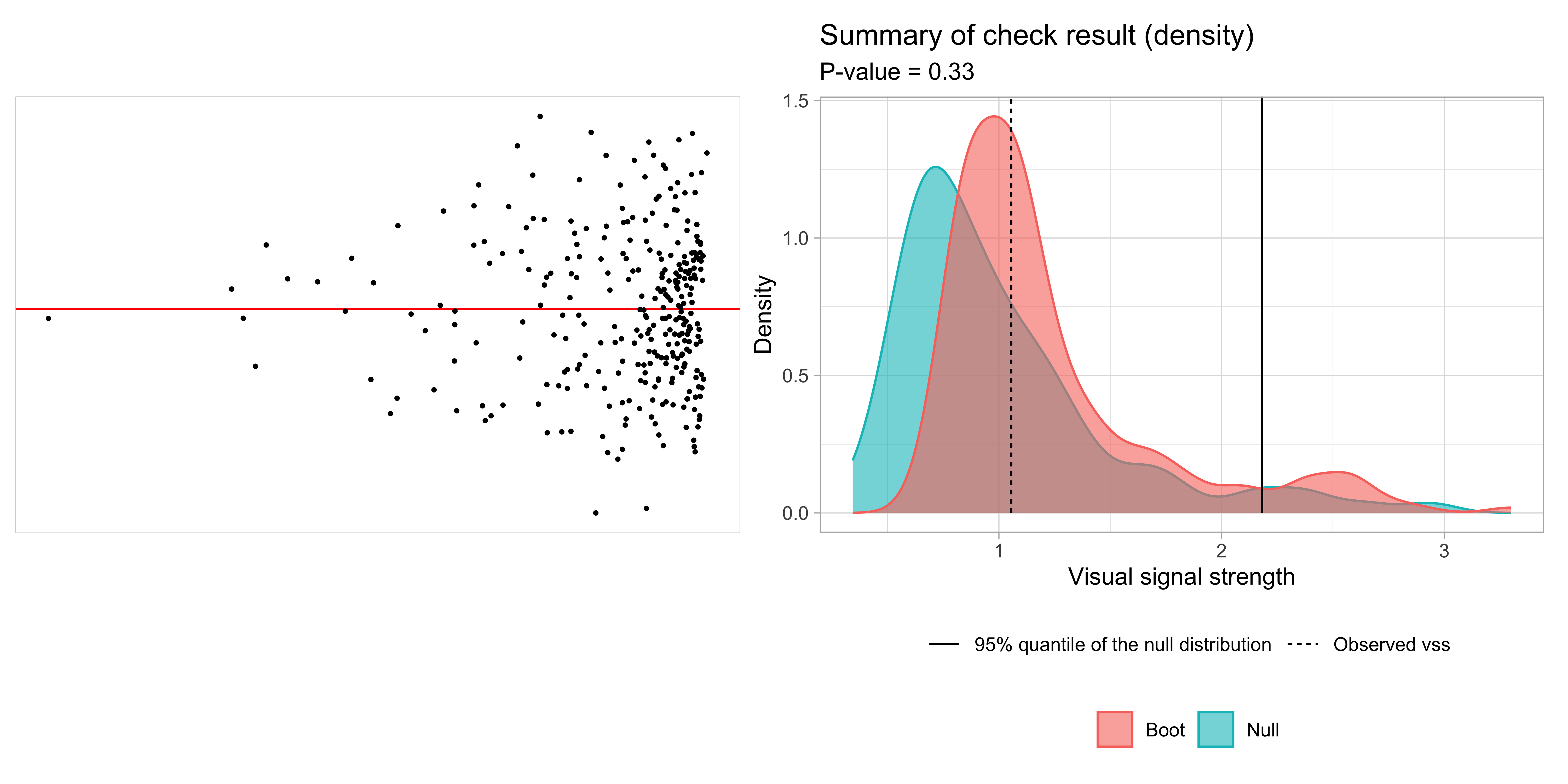
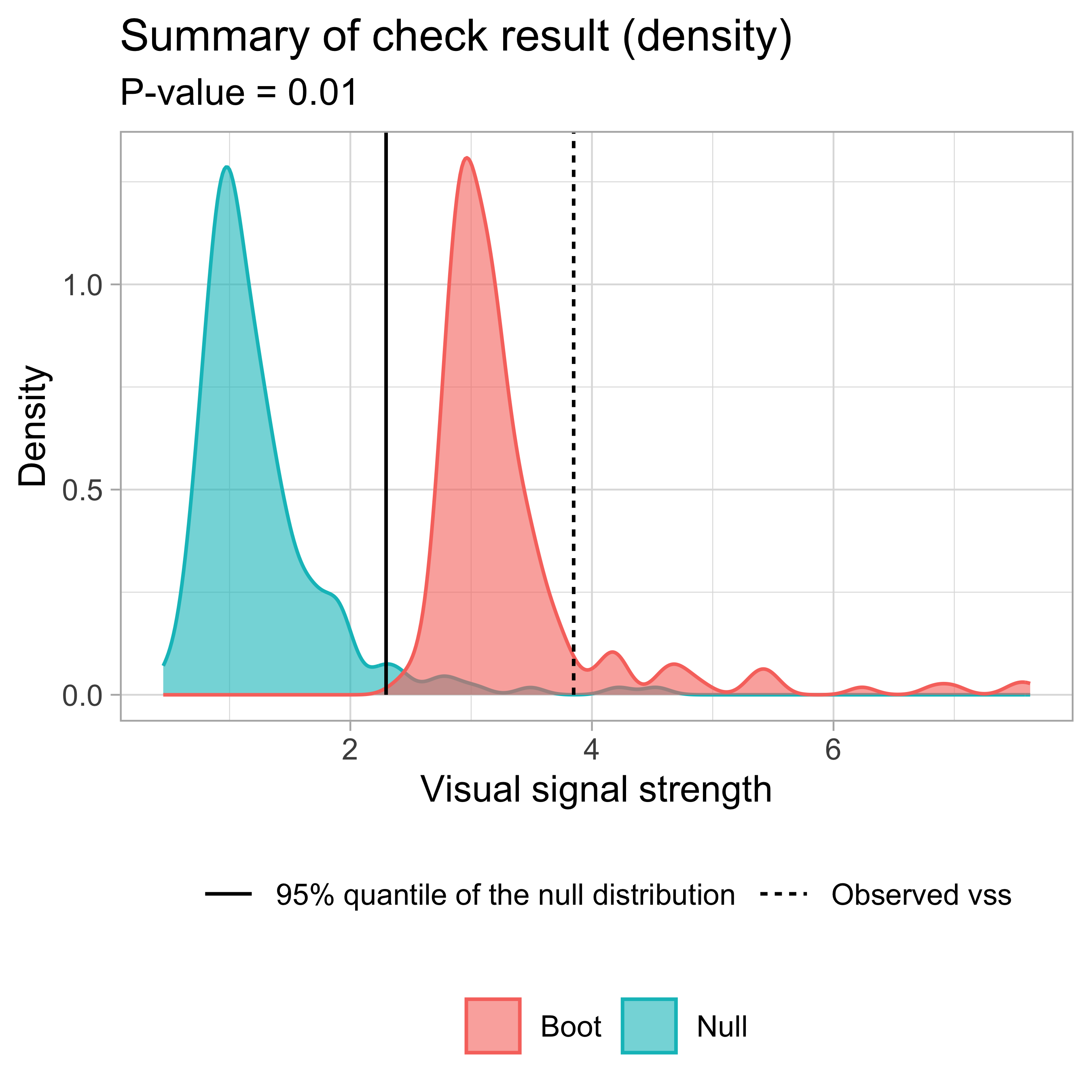
🔬Statistical Testing
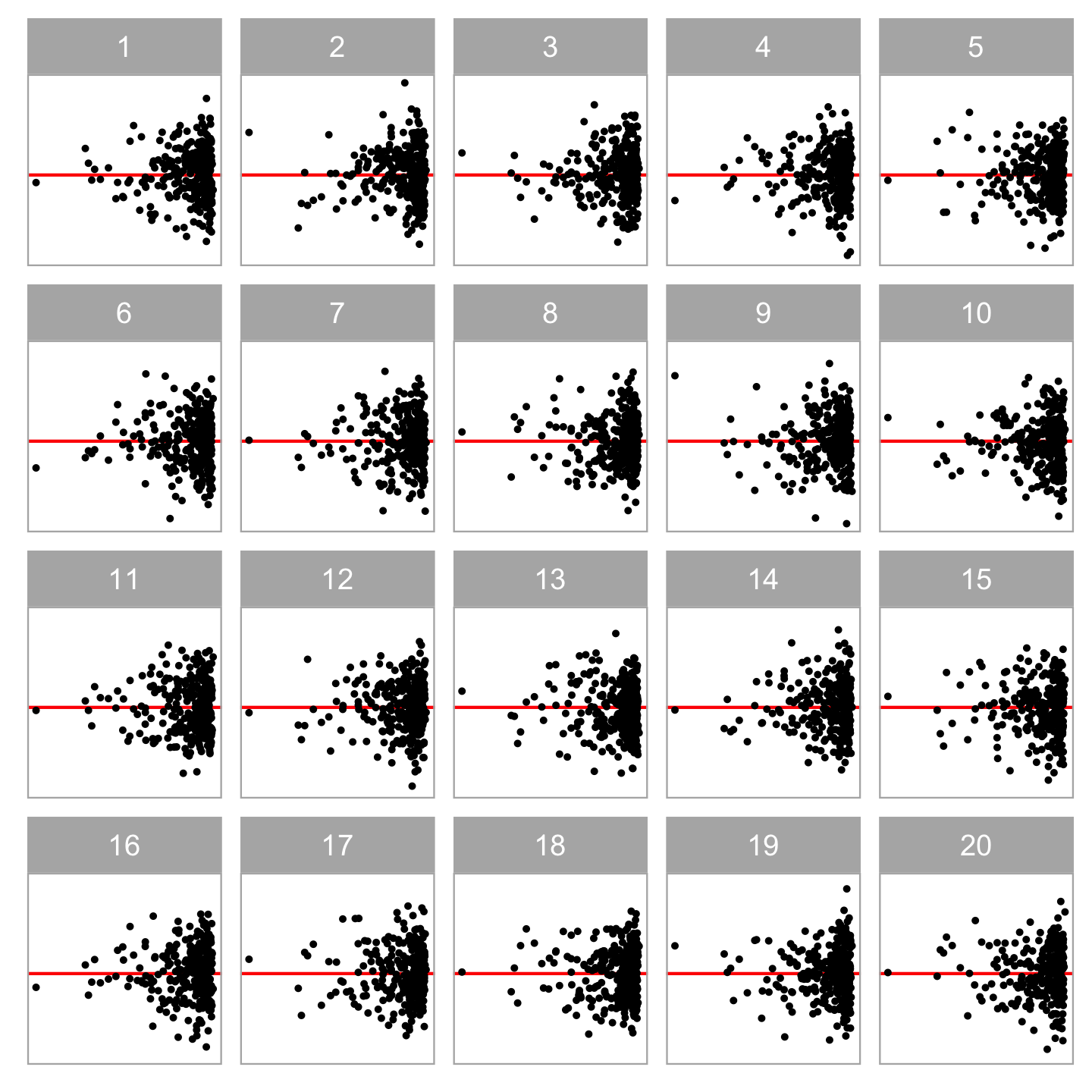
The null distribution can be estimated by predicting \(\widehat{D}\) for a large number of null plots.
The critical value can be estimated by the sample quantile (e.g. \(Q_{null}(0.95)\)) of the null distribution.
The \(p\)-value is the proportion of null plots having estimated distance greater than or equal to the observed one.
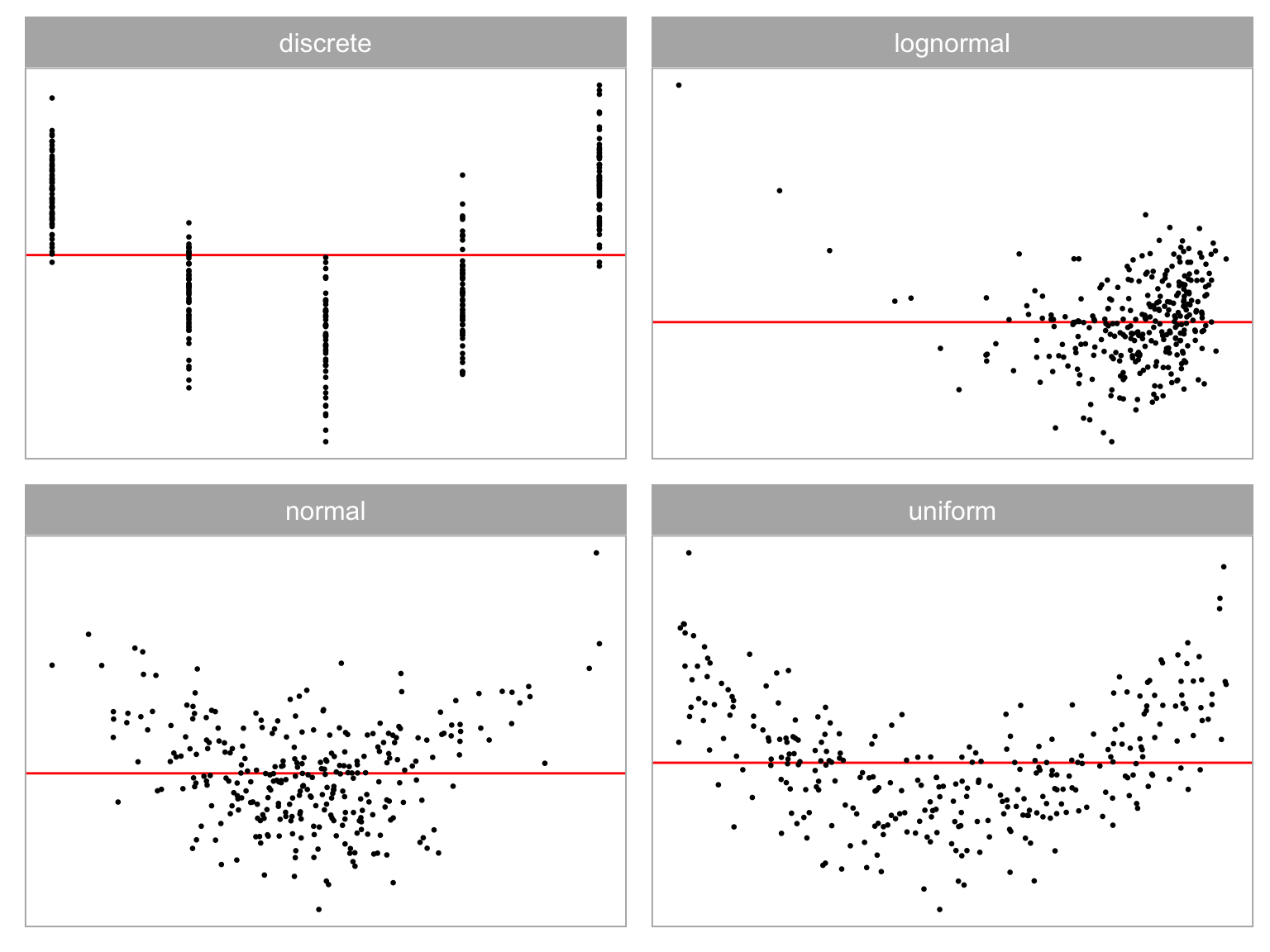
💡Training: Various Model Violations
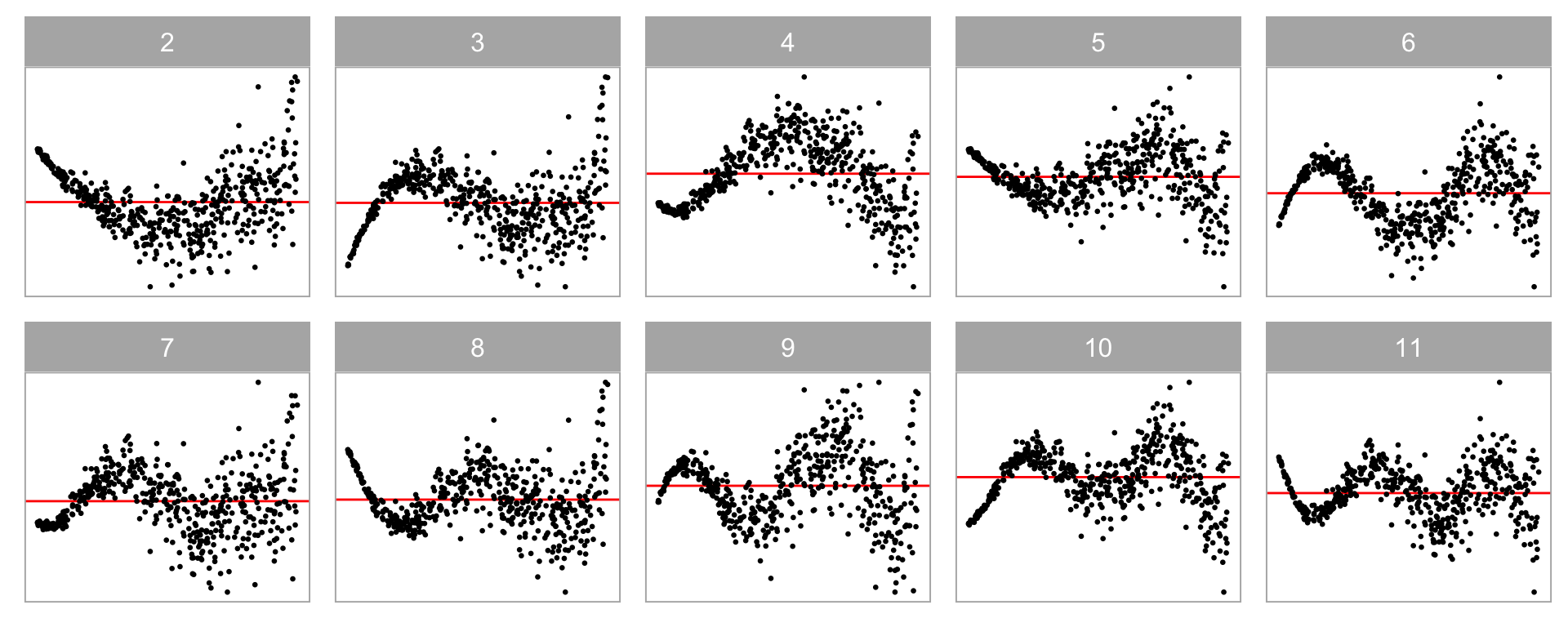
Non-linearity + Heteroskedasticity
Non-normality + Heteroskedasticity
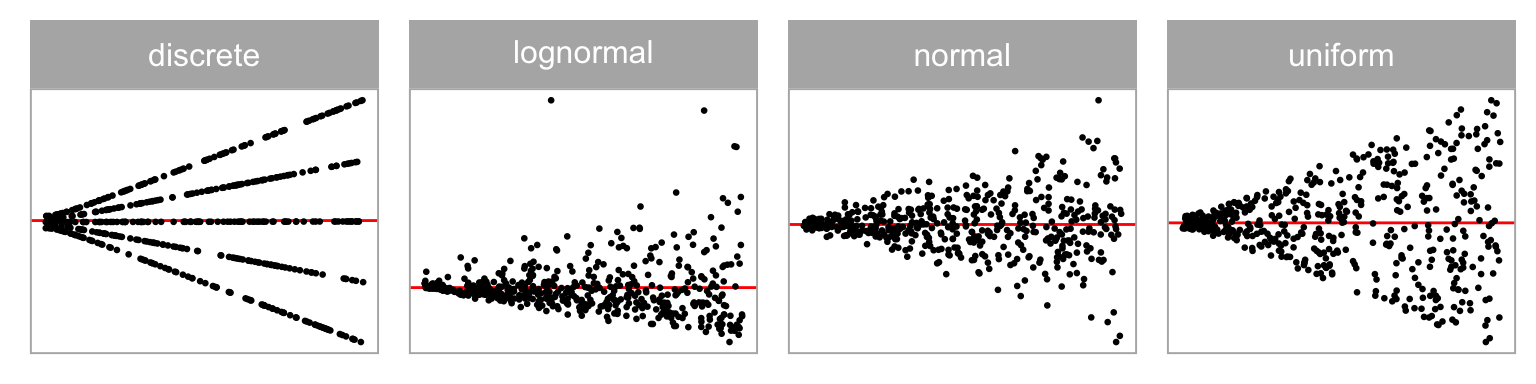
💡Training: Predictor Distribution
Distribution of predictor
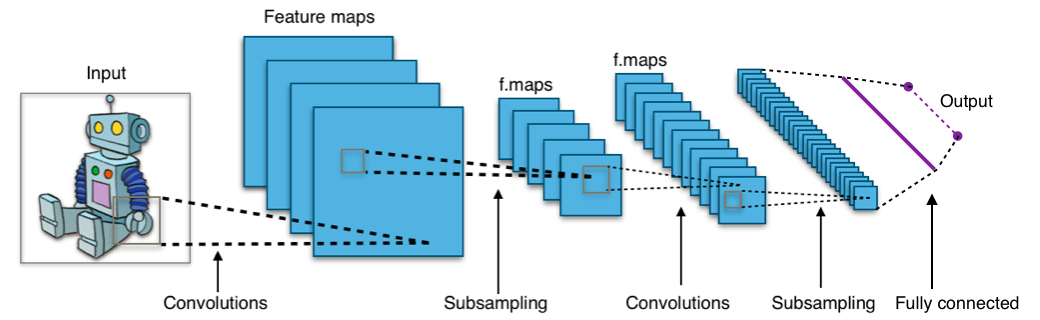
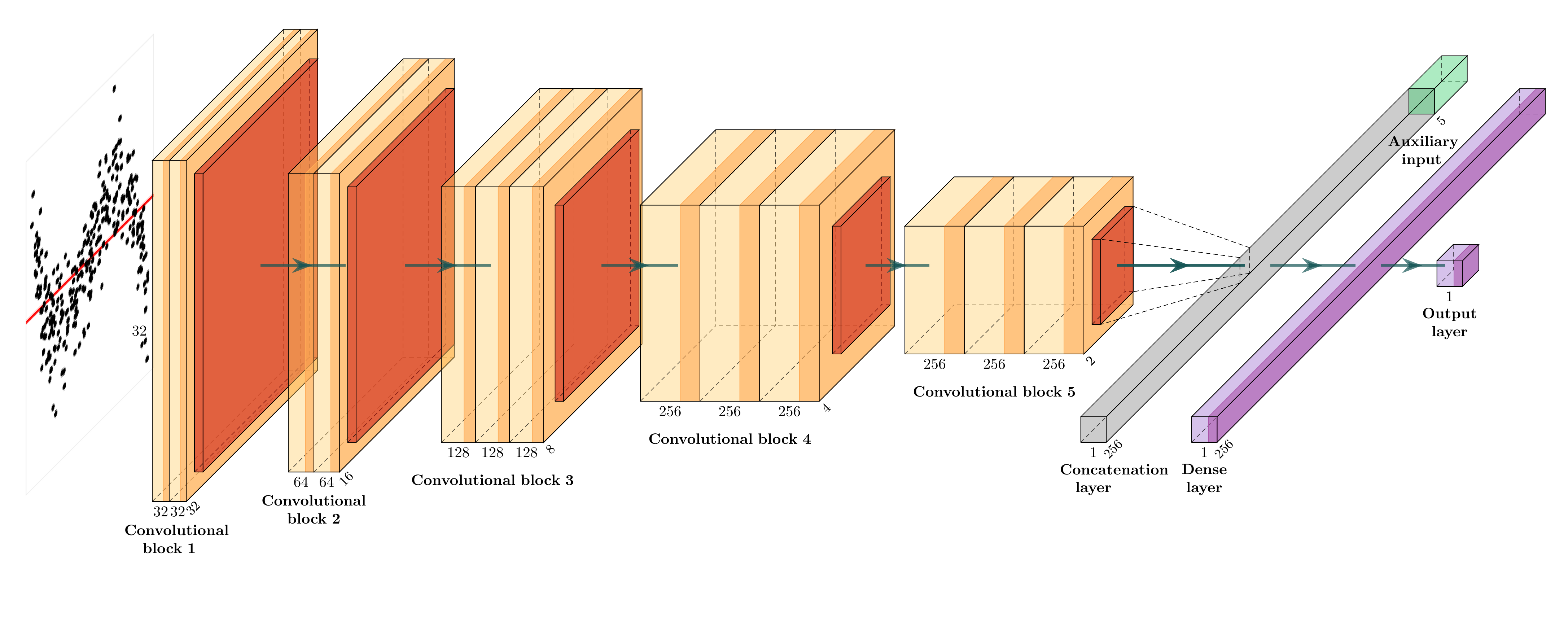
🏛️Model Architecture
The architecture of the computer vision model is adapted from VGG16 (Simonyan and Zisserman 2014).
autovi Package
The autovi package provides automated visual inference with computer vision models. It is available on CRAN and Github.